The GWAS Catalog provides a consistent, searchable, visualisable and freely available database of SNP-trait associations, which can be easily integrated with other resources.
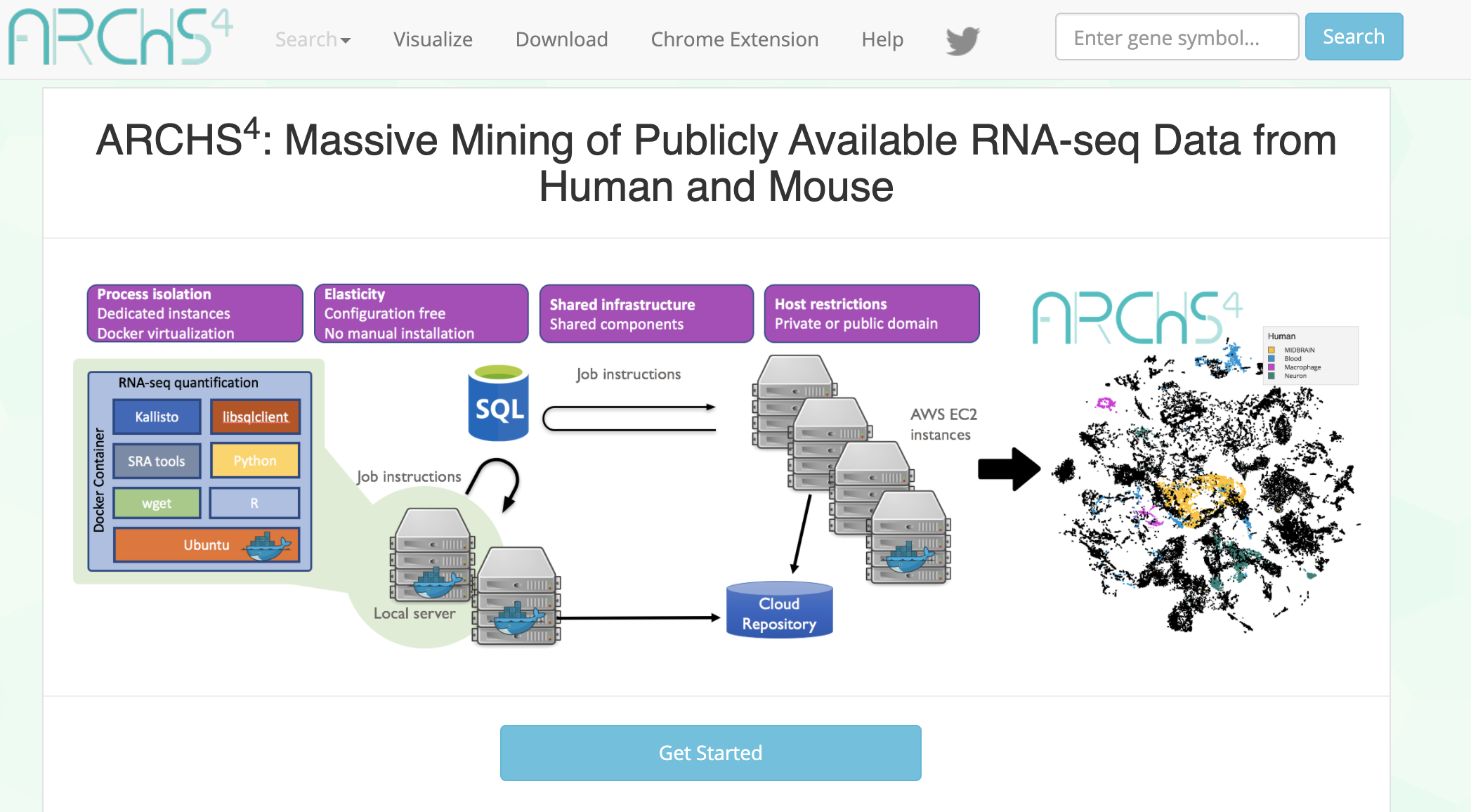
ARCHS4 provides access to gene counts from HiSeq 2000, HiSeq 2500 and NextSeq 500 platforms for human and mouse experiments from GEO and SRA.
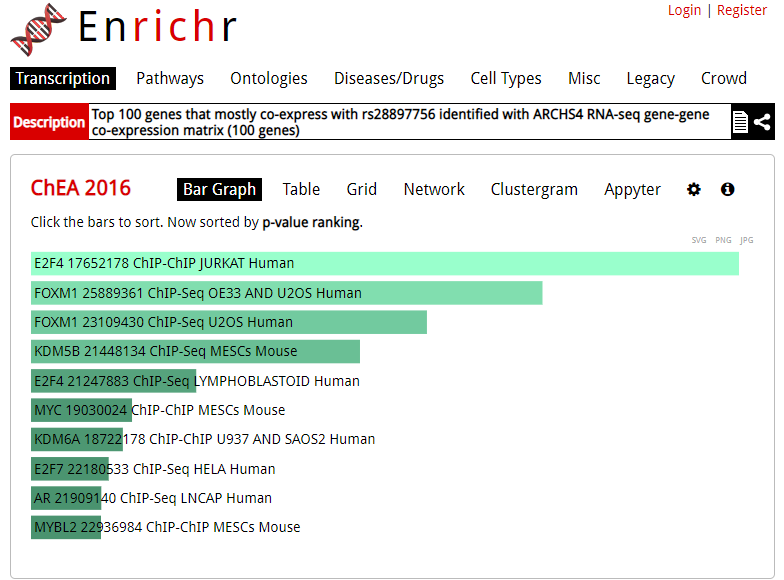
Enrichr is an enrichment analysis tool that provides various types of visualization summaries of collective functions of gene sets.
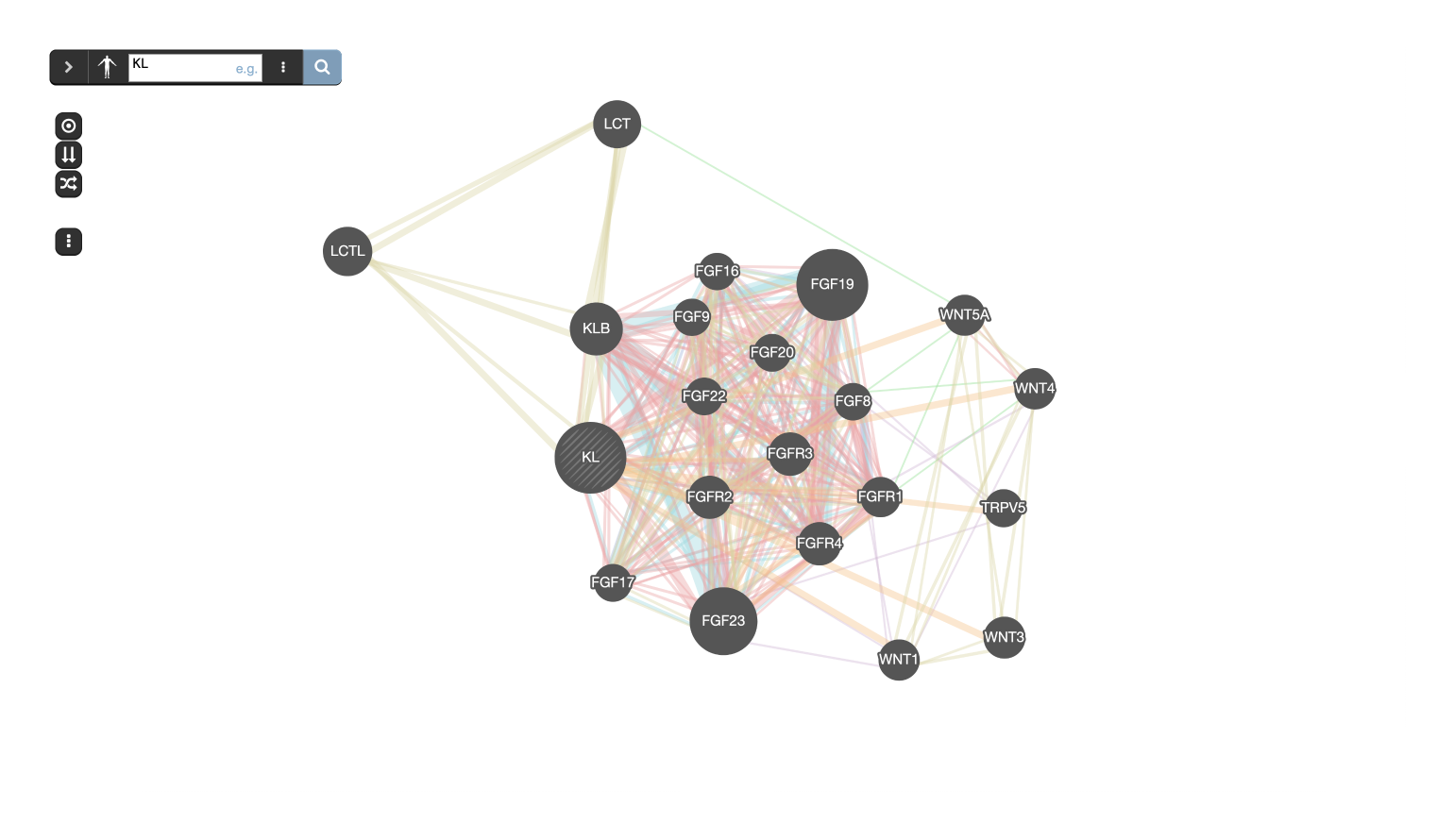
GeneMANIA builds subnetworks around an input gene using functional association data.
The Harmonizome is a collection of knowledge about genes and proteins from 114 datasets created by processing 66 online resources to facilitate discovery via data integration.
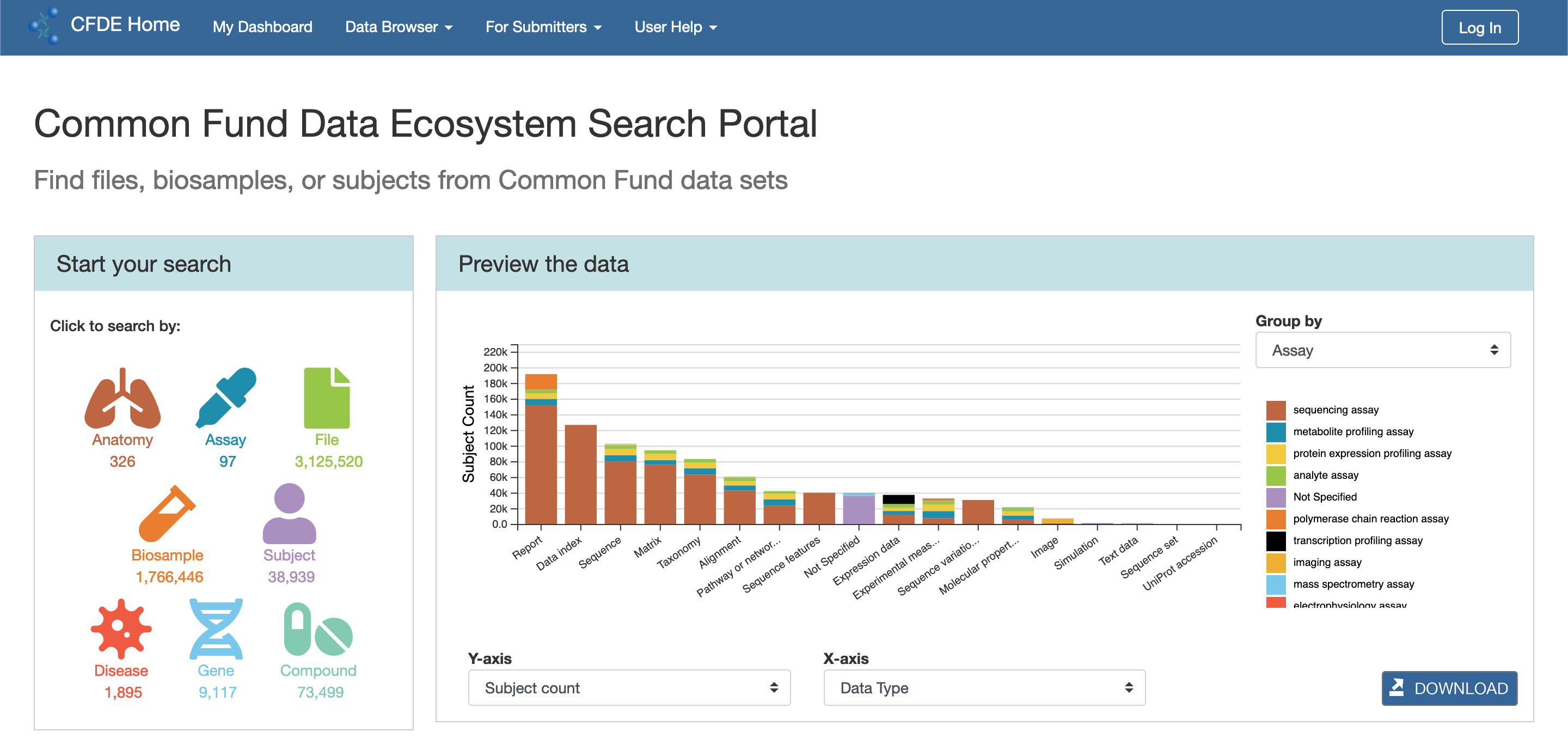
The CFDE Search Portal is a hub for searching the CFDE data across all programs. The main page of the portal (shown below) is meant for high-level decision-making, whereas the repository (or “data browser”) allows users such as clinical researchers, bioinformatics power users, and NIH program officers to search for CFDE data.
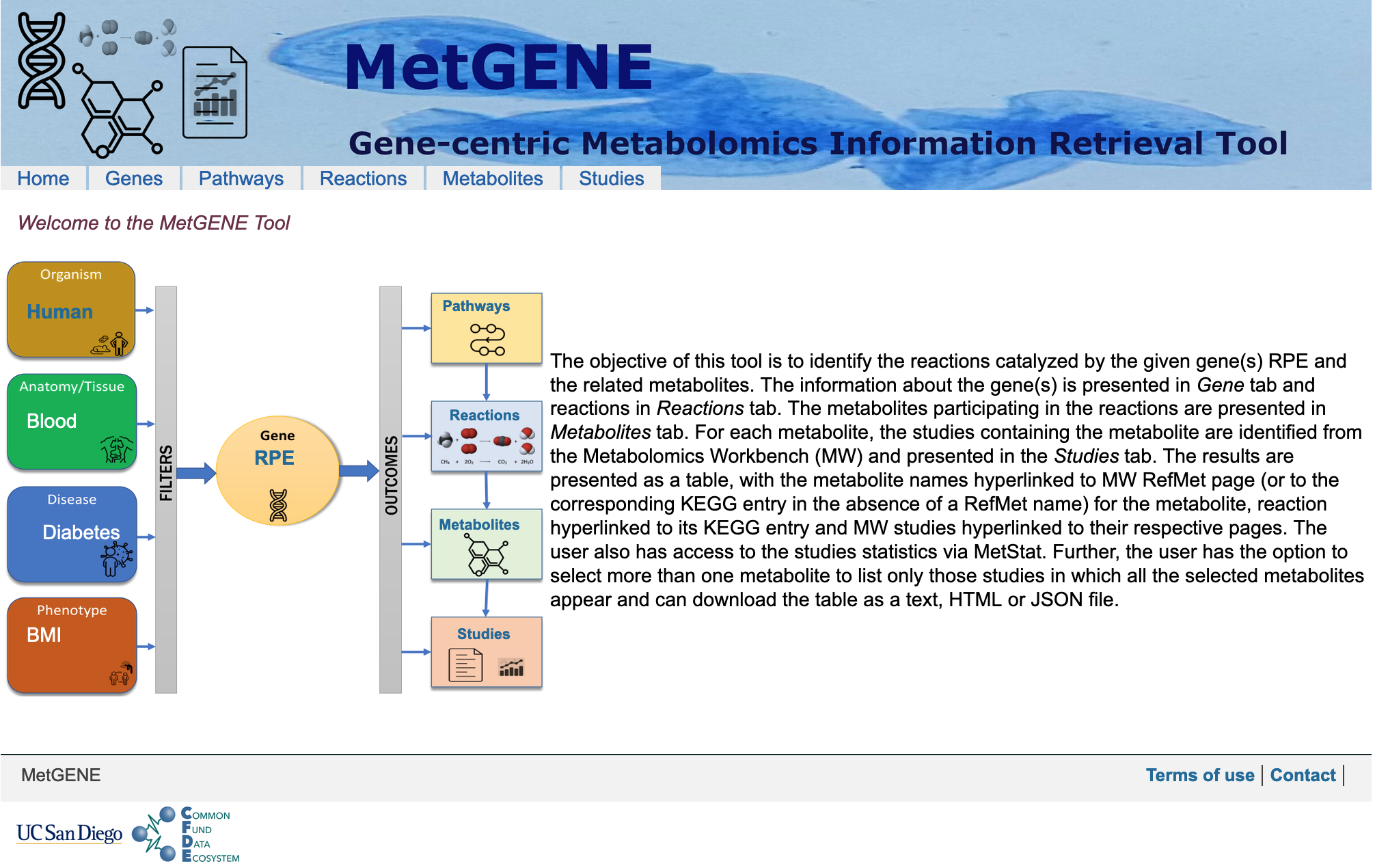
The objective of MetGENE is to identify the reactions catalyzed by the given gene(s) RPE and the related metabolites.
The Genotype-Tissue Expression (GTEx) Portal provides open access to data including gene expression, QTLs, and histology static.
Reactome is a free, open-source, curated and peer-reviewed pathway database that provides intuitive bioinformatics tools for the visualization, interpretation and analysis of pathway knowledge.
Therapeutic Target Database (TTD) is a database to provide information about the known and explored therapeutic protein and nucleic acid targets, the targeted disease, pathway information and the corresponding drugs directed at each of these targets.
SigCom LINCS data portal serves LINCS datasets and signatures. It provides a signature similarity search to query for mimicker or reverser signatures.
The RGCSRS Appyter provides visualizations of the RNA-seq signatures induced by CRISPR knockouts and chemical perturbagens. Signatures are computed from transformed data profiles from the LINCS L1000 data.
IDG Reactome Portal provides biologist-friendly way to visualize proteins, complexes, and reactions in high-quality Reactome pathways.
MARRVEL enables users to search multiple public variant databases simultaneously and provides a unified interface to facilitate the search process.
AlphaFold DB provides open access to protein structure predictions for the human proteome and 20 other key organisms to accelerate scientific research.
COSMIC, the Catalogue Of Somatic Mutations In Cancer, is the world's largest and most comprehensive resource for exploring the impact of somatic mutations in human cancer.
The Pharos interface provides facile access to most data types collected by the Knowledge Management Center for the IDG program.
The Monarch Initiative is an integrative data and analytic platform connecting phenotypes to genotypes across species, bridging basic and applied research with semantics-based analysis.
Gene Centric GEO Reverse Search Appyter enables users to query for a gene in a species of interest; it returns an interactive volcano plot of signatures in which the gene is up- or down-regulated.
PDBe Knowledge Base is a community-driven resource managed by the PDBe team, collating functional annotations and predictions for structure data in the PDB archive.
The Knockout Mouse Programme - International Mouse Phenotyping Consortium (KOMP-IMPC) has information about the functions of protein-coding genes in the mouse genome.

MGI is the international database resource for the laboratory mouse, providing integrated genetic, genomic, and biological data to facilitate the study of human health and disease.
CFDE Gene Partnership uses FAIR APIs from different DCCs to find and present gene-centric knowledge.
Automated Vector Quantization of Massive Co-expression RNA-seq Data Improves Gene Function Prediction (PrismEXP) is a new statistical approach for accurate gene function prediction.
Bgee is a database for retrieval and comparison of gene expression patterns across multiple animal species.
STITCH is a database of known and predicted interactions between chemicals and proteins and a functional enrichment tool.
BioGPS is a free extensible and customizable gene annotation portal, a complete resource for learning about gene and protein function.
KEGG is a database resource for understanding high-level functions and utilities of the biological system from molecular-level information.
STRING is a database of known and predicted protein-protein interactions and a functional enrichment tool covering more than 5000 genomes.
GlyGen provides computational and informatics resources and tools for glycosciences research using information from many data sources.
WikiPathways was established to facilitate the contribution and maintenance of pathway information by the biology community.
The Human Genome Browser includes a broad collection of vertebrate and model organism assemblies and annotations, along with a large suite of tools for viewing, analyzing and downloading data.
The Metabolomics Workbench serves as a repository for metabolomics data and metadata and provides analysis tools.
ClinGen is a NIH funded resource dedicated to building a central resource that defines the clinical relevance of genes and variants for use in precision medicine and research.
The HGNC database is a curated online repository of approved gene nomenclature, gene groups and associated resources including links to genomic, proteomic and phenotypic information.
The Open Targets Platform is a comprehensive tool that supports systematic identification and prioritisation of potential therapeutic drug targets by integrating publicly available datasets including data generated by the
The mission of UniProt is to provide the scientific community with a comprehensive, high-quality and freely accessible resource of protein sequence and functional information.
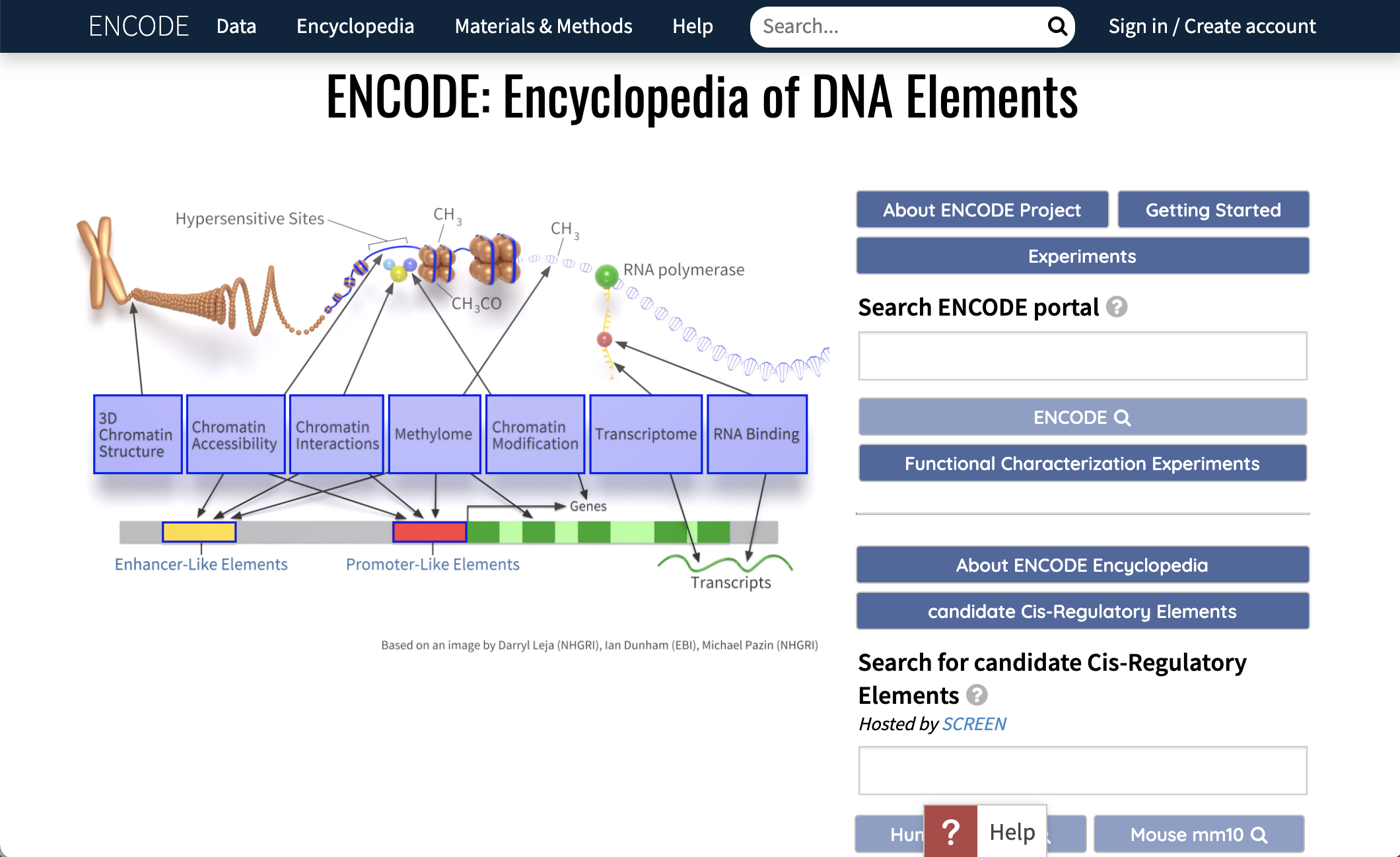
The ENCODE Consortium not only produces high-quality data, but also analyzes the data in an integrative fashion.
The Human Protein Atlas aims to map all human proteins in cells, tissues and organs using the integration of various omics technologies.
OMIM is a comprehensive, authoritative compendium of human genes and genetic phenotypes that is freely available and updated daily.
The NCBI Gene Database page provides information about nomenclature, RefSeqs, maps, pathways, variations, phenotypes, and links to genome-, phenotype-, and locus-specific resources.
PDB has information about the 3D shapes of proteins, nucleic acids, and complex assemblies that contribute to understanding everything from protein synthesis to health and disease.

PubMed comprises more than 33 million citations for biomedical literature from MEDLINE, life science journals, and online books.
The exRNA Atlas is the data repository of the Extracellular RNA Communication Consortium (ERCC). The repository includes small RNA sequencing and qPCR-derived exRNA profiles from human and mouse biofluids.
The Gene Ontology (GO) knowledgebase is the world’s largest source of information on the functions of genes.
GeneCards is a searchable, integrative database that provides comprehensive, user-friendly information on all annotated and predicted human genes.
GENEVA allows you to identify RNA-sequencing datasets from the Gene Expression Omnibus (GEO) that contains conditions modulating a gene or a gene signature.
The Open Targets Genetics Portal is a tool highlighting variant-centric statistical evidence to allow both prioritisation of candidate causal variants at trait-associated loci and identification of potential drug targets.
The goal of the Common Fund's Protein Capture Reagents Program is to develop a community resource of renewable, high-quality protein capture reagents, such as antibodies, with a focus on the creation of transcription factor reagents and testing next generation capture technologies.
This page contains information about genetic changes that were identified in a UDN participant.
Wikipedia is a free content, multilingual online encyclopedia written and maintained by a community of volunteers through a model of open collaboration, using a wiki-based editing system
Ensembl is a genome browser for vertebrate genomes that supports research in comparative genomics, evolution, sequence variation and transcriptional regulation.